What Can You Do With 100 Million Photos and Videos?
Part of the YLI-MED Corpus, released September 1
Back in July, we announced that ICSI’s Audio and Multimedia team is working with Yahoo Labs and Lawrence Livermore National Laboratory to process and analyze 100 million photos and videos publicly available under Creative Commons licenses. At more than 50 terabytes, the collection, the Yahoo Flickr Creative Commons 100 Million, is believed to be the largest corpus of user-generated multimedia publicly available for research.
Well, get ready – the team has begun to release resources and tools for researchers to use with the corpus. On September 1, the team released full sets of three audio features for the nearly 800,00 videos in the corpus, computed on LLNL’s Cray Catalyst supercomputer. Audio features, or statistical representations of sound, are used commonly in speech and audio recognition. The features released on September 1 are Mel frequency cepstral coefficients, Kaldi pitch, and subband autocorrelation classification, and more are coming soon. These can be used to build and train systems that automatically analyze the content of media with audio, such as videos.
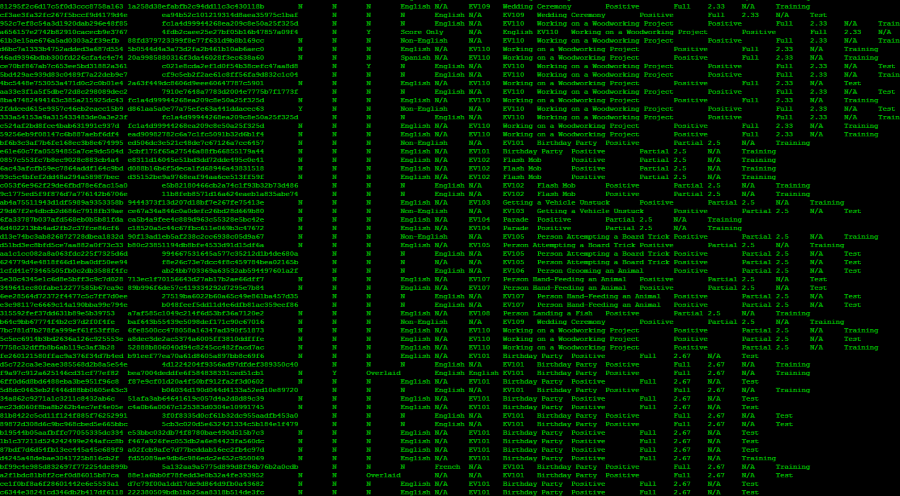
The team also released an annotated index of more than 50,000 videos selected from the corpus. The index categorizes videos that depict 10 “events” based on events used in the 2011 multimedia Event Detection task of the National Institute of Standards and Technology’s TRECVID Evaluation, which challenged participants to build systems that could find videos of the events. One of the events, for example, is “getting a vehicle unstuck.” The new YLI-MED index released by the team lists 2,000 videos that each depict an event and 48,000 that do not, providing researchers plenty of counter-examples to train systems.
Users can obtain the features associated with the indexed event videos by cross-referencing the unique identifiers in the index with those in the feature files for the whole corpus. In October, the team plans to release bundles with just the associated feature sets for the videos in the YLI-MED index. The team is working on extracting additional audio features from all of the videos as well as motion features to supplement the audio features they’ve already extracted.
Also on September 1, the team released a demo of audioCaffe, the first version of the framework being built for the SMASH project. The goal of the project is to create a media-analysis tool that can be run on parallel machines (which significantly speeds up the time it takes to analyze media) and that can serve as a single framework for a variety of tasks like speech recognition, audio analysis, and video event detection. SMASH is funded by a National Science Foundation grant.
The set of features and the annotated indices are being held in the Yahoo-Lawrence-ICSI (YLI - read “wily”) Corpus. More releases for the corpus are coming up, including four batches of visual features for the images and keyframes from the videos and a video index for five new events.
Learn more about the YLI Corpus.