Researchers seek new ways to enhance ability to run grassroots campaigns
Researchers at the International Computer Science Institute (ICSI) in Berkeley, Calif., are working on designing technological tools to make grassroots campaigns less expensive and more effective.
The team, led by longtime neural network and speech processing specialist Nelson Morgan, aims to use computational methods such as machine learning—the science of learning from examples and using the systems that result to complete functions without explicit instructions—to help reduce the influence money has on politics.
“Money from wealthy individuals and corporations distort the democratic process, but there is little relief in store from legislation or court action,” Morgan said. “Relief from legislative action is going to be difficult, but what if technology enabled a more efficient and lower cost approach? Technology could make Washington’s inability to handle this problem less important.”
On Thursday, May 28, 2015, Nelson Morgan, the former director of ICSI and the founding director of ICSI's Speech Group, gave a talk on recent results in speech and vision processing. You can watch it on YouTube or below.
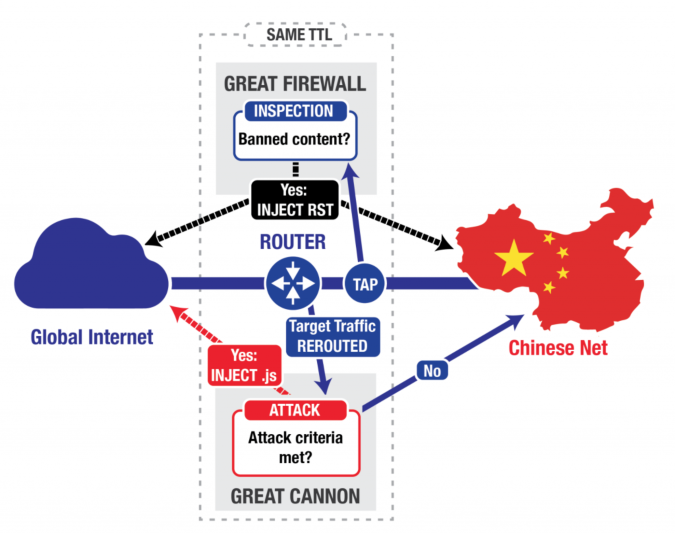
The Chinese government appears to have used distributed denial-of-service attacks against a nonprofit organization, GreatFire.org, that helps Chinese users circumvent the administration’s Internet censorship regime, according to a report by the Citizen Lab at the University of Toronto’s Munk School of Global Affairs that ICSI researchers collaborated on.
It's been five years since Gerald Friedland, then a researcher in the Speech Group, and Robin Sommer of Networking published "Cybercasing the Joint: On the Privacy Implications of Geo-Tagging" as an ICSI technical report. Quite a bit has changed around here in the meantime (Gerald now directs a new group, Audio and Multimedia, and Networking has been renamed Networking and Security to reflect the priorities of the group), but we're still working on ways to make sure that people know how to protect their privacy on the Internet.
In honor of the report's fifth birthday, here's a selection from our archives on privacy. You can also check out the Teaching Privacy web site and our recent newsletter feature on privacy.
In March, we were honored to host three speakers, including an alumnus of our visiting program. Oliver Kramer, now a juniorprofessor at the University of Oldenburg, Germany, was a postdoc sponsored by the German Academic Exchange Service, or DAAD, in 2011.
Florian Michahelles of Siemens gave the first talk in a new series, the Rubric, that features our senior researchers.
And Professor Paul Müller of the University of Kaiserslautern dropped by to speak about his institution's virtual laboratory for distributed systems research.
Damian Borth is a postdoc in the Audio and Multimedia Group, visiting us on a DAAD-funded postdoc. In his past work, he's looked at visual sentiment analysis, a useful tool for analyzing social multimedia posts - those that incorporate, say, text and images - since text often doesn't convey the whole meaning of a post.
Each year, ICSI holds an open house in conjunction with the Berkeley EECS Annual Research Symposium, or BEARS. At this year's open house, on Thursday, February 12 at 12:45 p.m., our researchers are going to present their work in areas as diverse as as speech recognition, big data, image sentiment analysis, and linguistics. We thought we'd give you some previews of the demonstrations and posters that our researchers will be showing throughout the afternoon.
In case you couldn't make it to the Annual Research Review on Friday, October 10, we've posted the videos on our YouTube channel. Check them out there or below.
Back in July, we announced that ICSI’s Audio and Multimedia team is working with Yahoo Labs and Lawrence Livermore National Laboratory to process and analyze 100 million photos and videos publicly available under Creative Commons licenses. At more than 50 terabytes, the collection, the Yahoo Flickr Creative Commons 100 Million, is believed to be the largest corpus of user-generated multimedia publicly available for research. Well, get ready – the team has begun to release resources and tools for researchers to use with the corpus.