Featured Research: Computer Vision
What kind of ICSI research could possibly tie together household service robots, wartime military operations, and an afternoon trip to IKEA? Trevor Darrell's newly formed Vision group does just that. Their work on computer vision enables recognition of objects, gestures, and even faces. As computer vision becomes more robust, it's finding applications identifying glassware, aiding in military planning, and even reuniting parents with their children.
Professor Trevor Darrell relocated from the CSAIL group at MIT and began working at ICSI in the summer of 2008. Joining him upon arrival were Dr. Raquel Urtasun and Mario Christoudias. In less than a year, the group has already grown to eight staff and student researchers here in Berkeley, also including Ashley Eden, Alex Shyr, Mario Fritz, Brian Kulis, Mathieu Salzmann, and Carl Ek. Meanwhile, Darrell is still advising his Ph.D. students who remain at MIT, Ariadna Quattoni, Tom Yeh, and Kate Saenko.
Darrell's group nominally revives Vision work that was done at ICSI in the 80's and 90's with Steven Omohundro and Chris Bregler, but is substantially different in both scope and function. The arrival of Darrell and his group to ICSI is a welcome elaboration on our other work on human–machine interfaces in the Speech and AI research groups. In addition to work done in poly–semantic word disambiguation, interactive image matching, and other fields, we highlight a couple of the group's current endeavors below.
REUNITE
Just before making the move to Berkeley, Trevor Darrell's group was approached by Children's Hospital Boston. They wanted his help finding a program that would assist them in disaster relief. The program they wanted would be able to sort through pictures of children who have been rescued from an emergency, and quickly identify them. The bad news was that the kind of technology they wanted didn't exist yet; the good news is that Darrell was able to partner with them and secure funding to develop it.
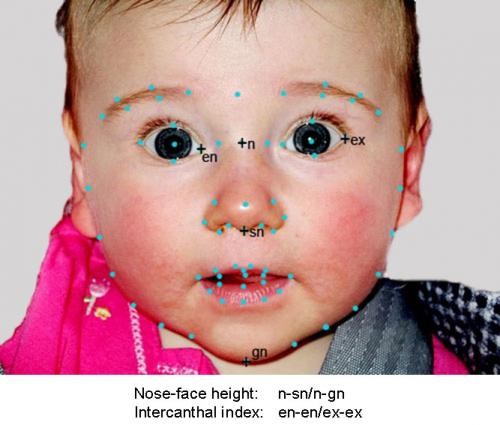
Ashley Eden and colleagues in the Vision group are now working on a system that can compile and analyze photos of children's faces to help reunite them with their parents. They hope to develop a system in which a user looks at two pictures and selects the one that looks more like the child they're trying to identify, thereby quickly homing in on the picture (and thus, location) of their own child. In order to do this, the group is determining which meaningful facial features are useful in which ways for comparative facial recognition, e.g. face shape, distance between the eyes, cheekbone position, etc., and identify mathematically significant correlations between faces that look alike. Once these features are identified, the group will construct algorithms that will help identify the target child based on similarities and differences between the reference pictures.
Hurricane Katrina exposed the frightening lack of emergency infrastructures. After the 2005 hurricane, it was 6 months until the last child was reunited with her family. In part, this is because there is no method for hospitals to document their unidentified children, and help parents search for them. Darrell's REUNITE project can dramatically augment rescue and relief efforts in large–scale disaster situations.
ROBOT VISION
Science fiction has filled our heads with the dream of human–like robots that can perform tasks ranging from mundane cleaning to world domination. Before functioning interactive robots could become a practical reality, researchers have a number of hurdles to overcome. Among these hurdles is the task of implementing robust robot vision, which members of the Vision group are developing with sponsorship from NSF, Toyota, and Menlo Park research start–up Willow Garage.
While it's easy for humans to identify everyday objects such as coffee cups, this poses a challenge for machines. Coffee cups can be made of a number of different materials, fall within a wide range of sizes, have a number of different shapes, come with or without various handle designs, and can be any color — including clear. With such a wide ranging set of variables for even a simple object, a robot has to be able to determine a lot of information through its visual sensors.
One thing working in the robot researcher's favor is the plethora of tagged images available online. With a simple Google image search for "coffee cup" returning nearly five million images, there is no shortage of training data. These data are not, however, of the most helpful quality. Current robot technology incorporates multiple sensors that utilize multi–spectral imaging to include qualities such as depth perception and infrared light information; information that is not present in the supply of internet images. This more complex multi–modal data is the most useful thing for training a robot to recognize an object, but there is not nearly as much information of this kind available. Darrell's group, along with researchers at Brown University and Willow Garage, is currently bridging the gap between the copious amount of web images and richer multi–modal data to allow robots to reap the benefits of both types of information and apply them to object recognition.
This brings us to IKEA; Darrell recently spent $300 and the better part of an afternoon there, purchasing one of every glass bowl and plate he could find. The group is building a test set of everyday objects to be catalogued using multi–spectral sensors, and developing a system which allows a robot to use high–level sensor information alongside the wealth of tagged web images. They are studying glassware for a number of reasons: the variability of individual items in a class mentioned above, so it makes for a good data set; robot vision currently has particular trouble with transparent objects, so it has the potential to work out another challenge for the field; and these are objects that household service robots will commonly need to interact with, so it will be directly applicable. The group hopes that the training data from using the glassware will inform future efforts of how to reconcile multi–modal sensor input with the abundance of tagged web images. It won't be too long before there's a robot you can ask to "bring me my Peet's coffee cup from the dining room table", and it will be able to!
STRATEGIC MILITARY PLANNING
The Vision group has also been contracted to do some work for the US Military. The group has undertaken two projects that both involve utilizing real–time sensor data in strategic Military planning. One project, URGENT, generates three–dimensional maps on the fly; the other project, ULTRA–Vis, uses a technique called "augmented reality" to enhance human vision.
DARPA's URGENT program aims to take sensor feeds, such as those from satellites or helicopters, and extract three–dimensional information to create highly detailed maps in near–real–time. When the work is complete, sensors will be able to detect a wide array of elements and objects in an image, and extract the information for use in automated map generation. ICSI's Vision group is developing the algorithms that will allow this system to recognize objects such as stop signs, power lines, bus stops, and even garbage cans. The algorithm works with three–dimensional imagery to accurately identify objects that are occluded, or blocked from direct view. The overall system then could take this object information and combine it with terrain and building features to generate a map within half an hour, allowing for fast and highly–accurate planning of operations. The level of detail these maps can provide is not dissimilar from Google's wire–frame maps of downtown San Francisco that contain transit information and other points of interest.
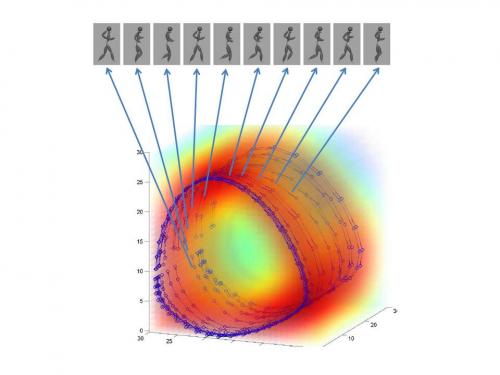
ULTRA–Vis aims to improve soldier functionality in urban areas. Military personnel are faced with many challenges when operating in urban environments; there are often large non–combatant populations in locations where noise makes radio communication difficult, and buildings obscure line–of–sight, thereby making gesture communication difficult. The Vision group's portion of this project involves gesture recognition on wearable sensors; they are developing machine learning algorithms for automatic recognition of soldiers' hand gestures. Personnel will have wearable computers with see–through displays that will augment their vision by overlaying the information over what they are already seeing.
GROUP FUTURE
Even with the innovative work currently underway, there are still huge leaps to be made in computer vision. Besides the difficulty with transparent objects mentioned above, there are large conceptual hurdles to overcome, as well. One application of computer vision that is seeing rapid development is in mobile phones. Although currently limited by sensor quality and onboard processing power, mobile phone image recognition is seeing success with two–dimensional, high–contrast items like posters and CD covers as well as popular landmarks. Advances in phone–based image recognition will require efficient algorithms and/or low–latency off–board processing.
While current object recognition algorithms require some kind of training or reference data, Darrell hopes to teach computers to understand the essence of what they're looking at. If a computer knows what properties constitute a chair, it will be able to make an intelligent — and more importantly, independent — determination that an object is or is not categorically a chair. The accuracy of this method would ideally parallel our own ability to recognize novel objects. When this kind of computational reasoning combines with affordable and highly portable sensors such as those on cell phones, there will be a wealth of information available about anything, just by pointing a camera at it.